Mình cho Claude Code "học thuộc" repo 4.300 file trong 2 phút, và đây là những gì mình đo được
Mình cài CodeGraph, index repo 4.304 file trong 2 phút 18 giây, query kiến trúc trả lời trong 1,97 giây. Số đo thật, screenshot thật, kèm cả lúc KHÔNG nên dùng.

Có một khoản tiền mình trả cho Claude Code hàng tháng mà mãi sau này mình mới để ý: tiền cho những câu trả lời "để em tìm đã".
Mỗi lần mình hỏi một câu kiến trúc kiểu "message từ Telegram đi qua những hàm nào trước khi agent trả lời", Claude Code không trả lời ngay. Nó phải grep, mở file, đọc, grep tiếp, mở file khác. Mỗi bước là một tool call, mỗi tool call là token, và token là tiền. Trên repo bé thì không sao. Trên repo vài nghìn file, riêng khâu "đi tìm" đã ngốn một phần đáng kể của session, trước khi model đọc được dòng code liên quan đầu tiên. Tài liệu của CodeGraph gọi thẳng khoản này là discovery tax, thuế khám phá. Mình thấy cách gọi này chuẩn: đó đúng là một loại thuế, và cái hay là thuế này có cách né hợp pháp.
Mình vốn có thói quen hễ thấy tool mới có số liệu đàng hoàng là phải kéo về chạy thử bằng được. Lần này là CodeGraph, sau khi đọc bài hướng dẫn trên blog Tosea.ai và README của dự án. Họ công bố những con số rất kêu: rẻ hơn ~35% chi phí API, giảm ~70% tool call. Số của người khác thì nghe cho vui thôi. Bài này là số của mình, đo trên máy mình, kèm screenshot từ chính terminal của mình.
CodeGraph là gì, nói kiểu dân kỹ sư
CodeGraph là một tool open-source (MIT, tác giả Colby McHenry) làm đúng một việc: index trước cả codebase thành một knowledge graph, để AI agent query index thay vì đi lục file.
Kiến trúc của nó gồm 3 lớp, lớp nào cũng là lựa chọn kỹ thuật có lý do:
- Tree-sitter parse code thành AST rồi bóc ra symbol, call graph, import graph. Điểm quan trọng: đây là bóc tách deterministic từ cú pháp code, không phải nhờ LLM "tóm tắt hộ", nên index chính xác và tái lập được.
- SQLite + FTS5 lưu toàn bộ graph trong thư mục
.codegraph/ngay trong dự án. Không server ngoài, không gửi code đi đâu, 100% local. Với người từng làm data như mình, chọn SQLite cho bài toán này là chọn đúng: một file, query nhanh, không vận hành gì thêm. - MCP server phơi graph này ra cho agent qua Model Context Protocol. Claude Code, Cursor, Codex CLI, OpenCode đều nói chuyện được. Agent gọi
codegraph_contextđể định vị vùng code,codegraph_exploređể lấy symbol kèm quan hệ, thường là xong mà không cần mở file nào.
Cài đặt đúng 3 lệnh:
npm install -g @colbymchenry/codegraph # cần Node 22 hoặc 24
codegraph install # đăng ký MCP vào Claude Code/Cursor/Codex
codegraph init # chạy trong thư mục dự án
Lab của mình: repo OpenClaw, 4.304 file
Nguyên tắc của mình khi viết về tool: chưa chạy thì chưa viết. Mình clone repo OpenClaw (framework agent mình đang vọc, hơn 4.300 file code, chủ yếu TypeScript) ra một thư mục lab riêng để nghịch thoải mái, rồi chạy codegraph init và bấm giờ.
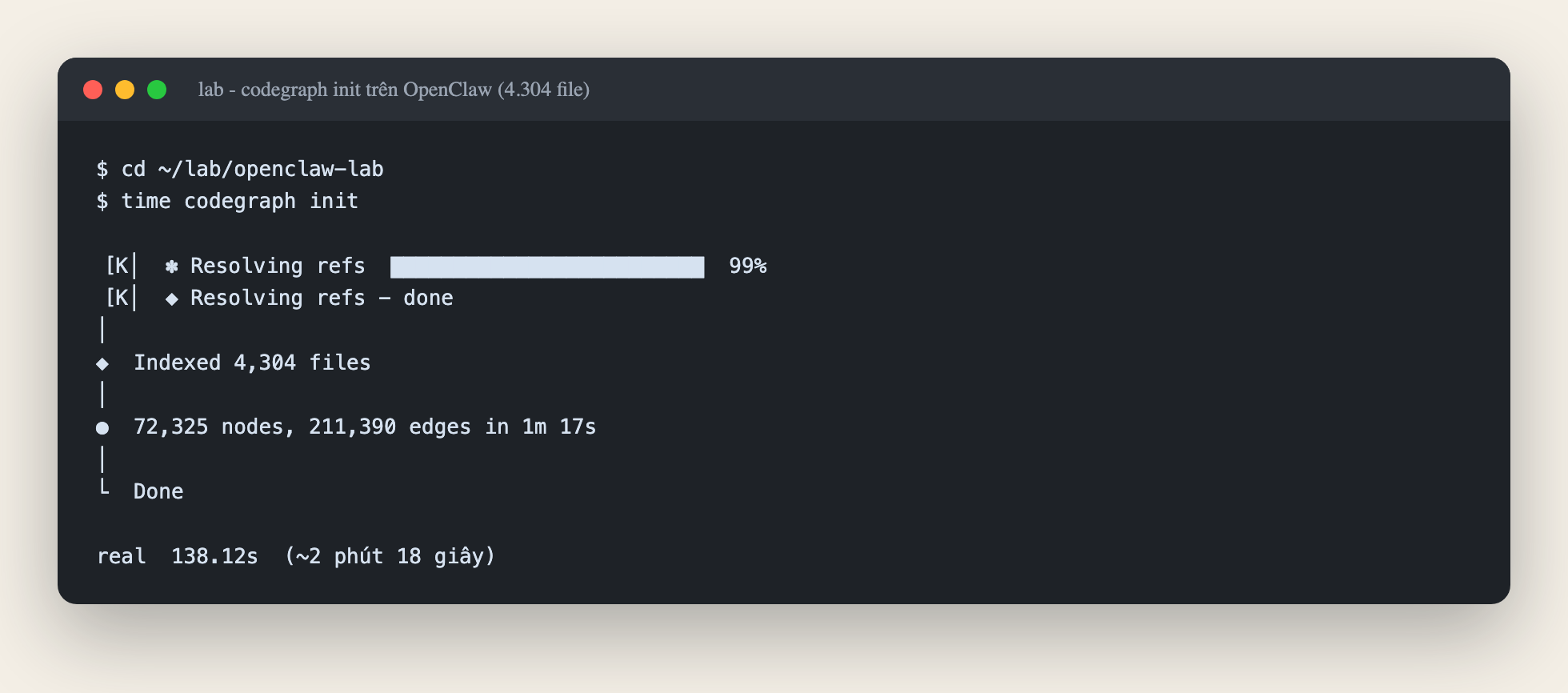
Kết quả trên máy mình (MacBook Apple Silicon):
- Index 4.304 file hết 2 phút 18 giây (bản thân CodeGraph báo 1 phút 17 giây cho khâu build graph, phần còn lại là scan file).
- Ra 72.325 node và 211.390 edge: từng function, class, import, route... và quan hệ gọi nhau giữa chúng.
- Database chiếm 183 MB trên đĩa. Con số này mình sẽ quay lại ở phần chê.
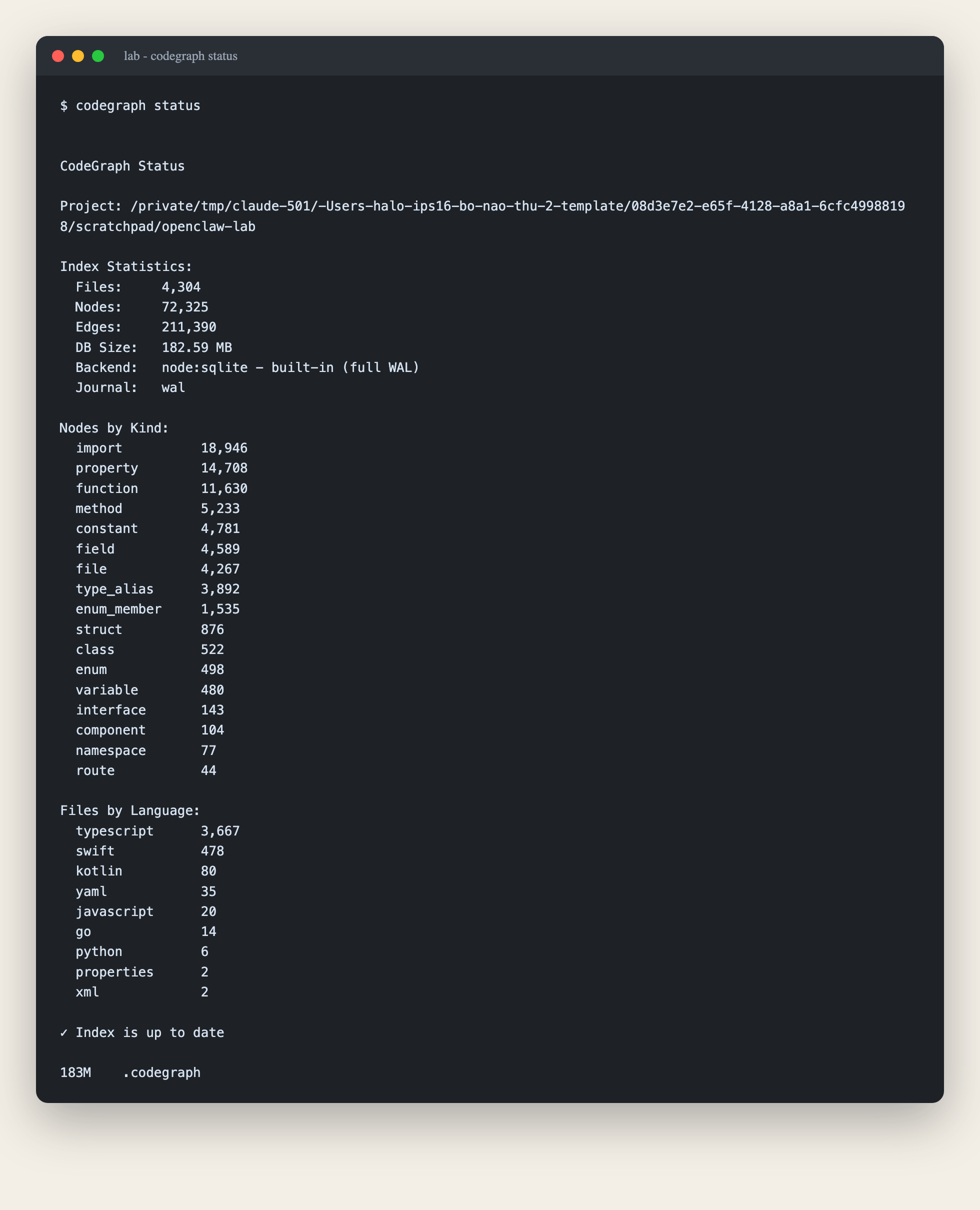
codegraph status xác nhận backend SQLite chạy native chứ không rơi về WASM (nếu thấy chữ wasm là hiệu năng chậm 5-10 lần, phải cài lại):
Phép đo ăn tiền: 1,97 giây thay cho một chuỗi grep
Giờ đến câu hỏi kiến trúc thật, đúng kiểu câu mình vẫn hỏi Claude Code hàng ngày: "một message Telegram đi vào hệ thống chảy qua đâu để agent sinh câu trả lời?"
Đường cũ, không có index, agent sẽ phải làm gì? Mình giả lập bằng tay:
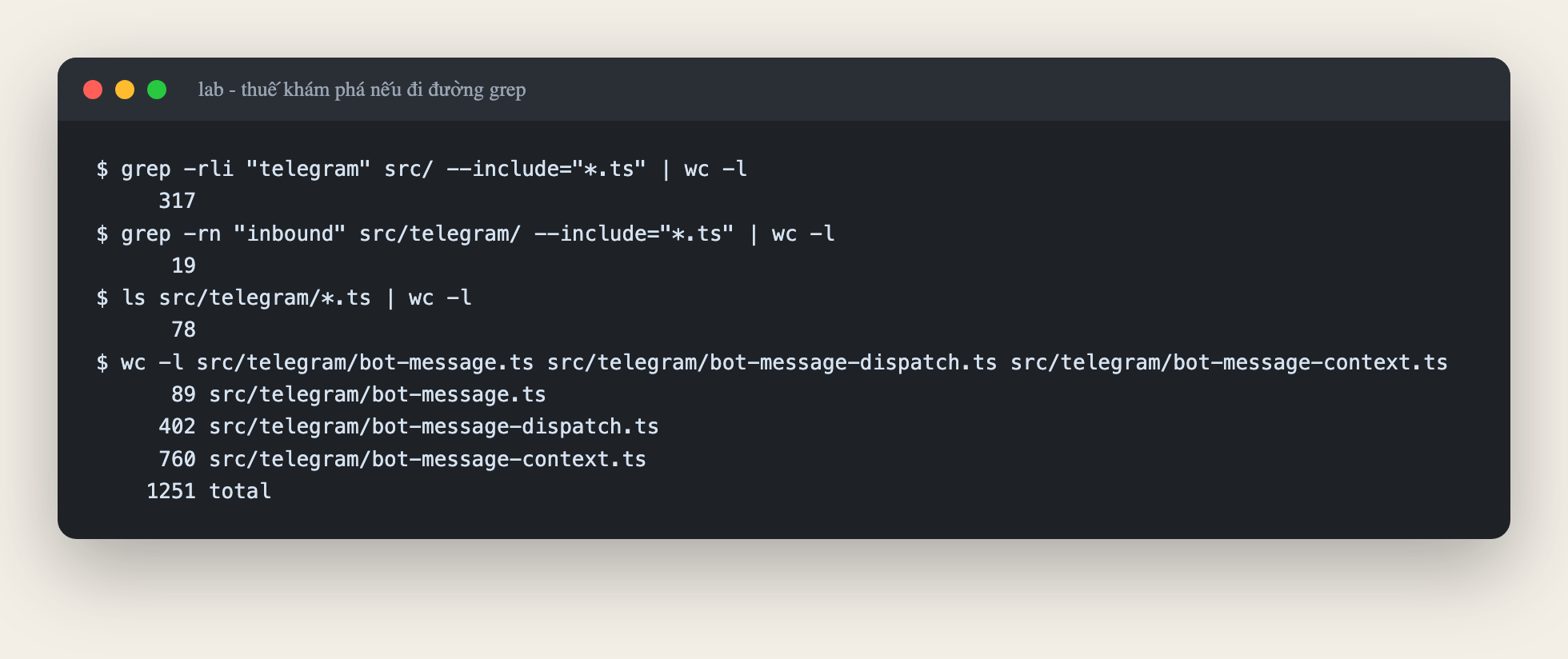
grep -rli "telegram"match 317 file. Chỉ riêng thư mụcsrc/telegram/đã có 78 file .ts.- Ba file thực sự liên quan dài tổng cộng 1.251 dòng, và muốn biết đó là ba file nào thì phải đọc kha khá file "gần đúng" trước đã.
Đấy chính là thuế khám phá: agent trả token cho từng lần thử sai đó, còn mình trả tiền và ngồi chờ.
Đường mới, một lệnh duy nhất:
codegraph explore "how does an inbound Telegram message flow to the agent and produce a reply"
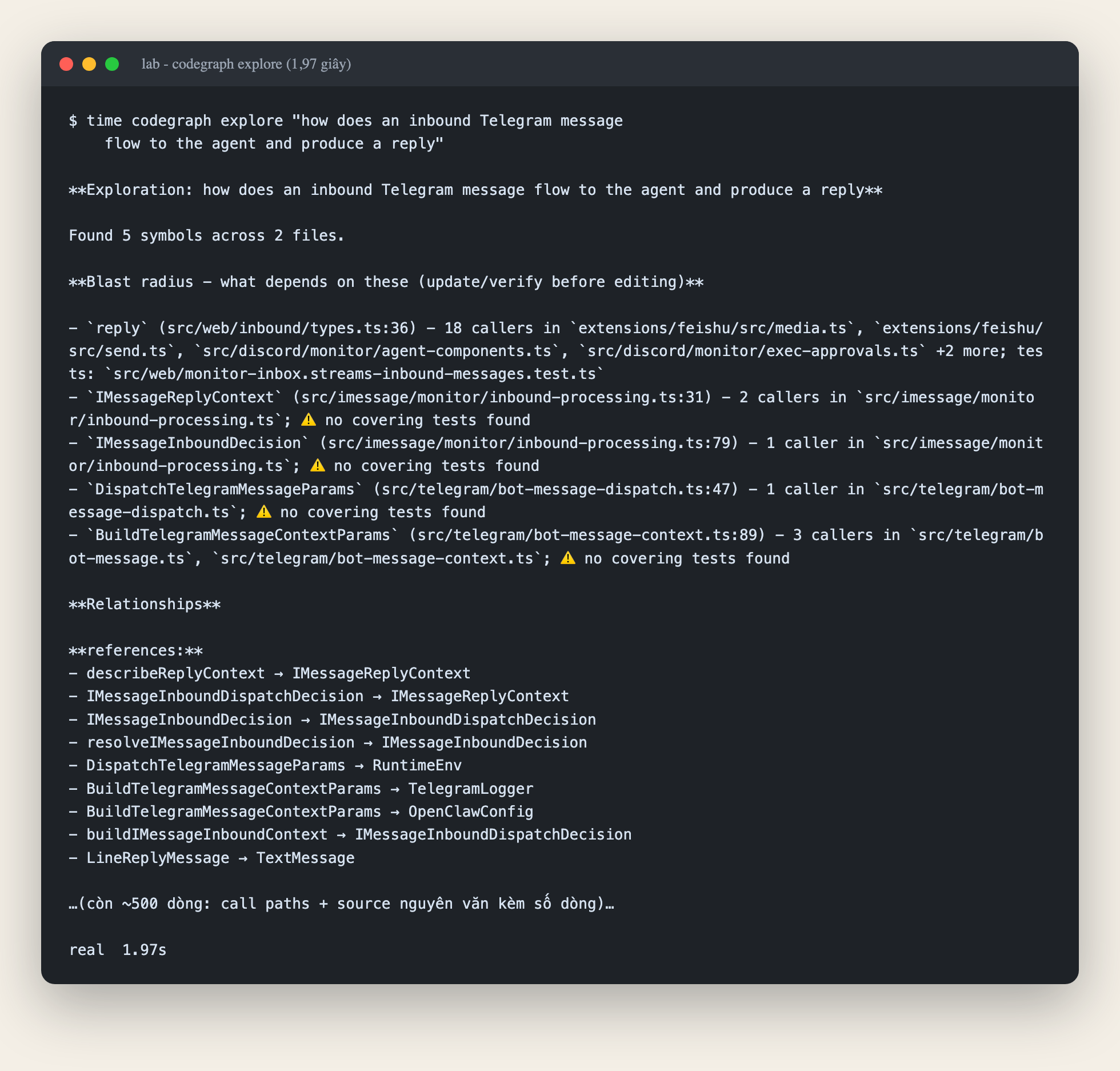
1,97 giây. Trả về đúng 5 symbol trong 2 file trung tâm của luồng dispatch message, kèm ba thứ khiến mình gật gù:
- Blast radius: sửa hàm
replythì 18 chỗ khác bị ảnh hưởng, liệt kê từng file. Đây vốn là câu hỏi mình sợ nhất khi refactor. - Cảnh báo "no covering tests found" cho những symbol chưa có test chạm tới. Tính năng này mình không ngờ tới, và nó hữu ích hơn nhiều lời hứa trên landing page.
- Source nguyên văn kèm số dòng, đọc từ đĩa tại thời điểm query chứ không phải cache cũ, nên agent không cần Read lại file.
Với Claude Code, khác biệt thực tế là: câu hỏi kiểu này trước đây kích hoạt một tràng grep/glob/Read (dự án CodeGraph benchmark trên repo 4.000 file là 40+ tool call), giờ còn 2-4 call MCP. Ít call hơn là ít token hơn, ít token hơn là hoá đơn nhẹ hơn và câu trả lời về nhanh hơn.
Số mình đo với số dự án công bố
Cho sòng phẳng, cần tách hai loại số:
Số mình tự đo hôm nay trên repo 4.304 file: init 2 phút 18 giây, index 183 MB, query explore 1,97 giây, câu hỏi kiến trúc gom về 2 file đúng thay vì 317 file ứng viên. Đấy là trải nghiệm thật, máy thật.
Số dự án công bố (benchmark trong README, chạy Claude Code headless trên 7 repo thật, 4 lần mỗi cấu hình, lấy median): rẻ hơn 35% chi phí API mỗi session, ít hơn 59% token, nhanh hơn 49%, ít hơn 70% tool call. Mình chưa tự chạy lại nguyên bộ benchmark này (mỗi arm là nhiều session Claude Code trả phí, mình sẽ làm một bài riêng đo trước-sau trên dự án thật của mình). Nhưng phương pháp họ mô tả đủ minh bạch để tái lập, và những gì mình đo được hôm nay nhất quán với hướng của các con số đó.
Một câu trong tài liệu của họ mà mình đánh giá cao vì dám nói thật: lợi ích tỉ lệ thuận với kích thước repo. Repo ~150 file thì grep vốn đã rẻ, gắn CodeGraph vào gần như không thấy khác biệt. Đừng kỳ vọng phép màu trên project bé.
Cái mình thích, cái mình chưa thích
Sau một buổi nghịch, cảm nhận thật của mình:
Thích:
- Triết lý "trả lời từ index, không lục file" đánh trúng đúng chỗ đau nhất về chi phí khi dùng coding agent trên repo lớn.
- Blast radius + cảnh báo thiếu test là hai tính năng vượt kỳ vọng.
- 100% local. Code không rời khỏi máy, điều mình bắt buộc phải cân nhắc khi làm việc với codebase không phải của mình.
Chưa thích:
- 183 MB index cho repo 4.300 file là nặng, gần bằng chính source code. Khuyến nghị chính thức là commit
.codegraph/vào git cho team dùng chung; với mình 183 MB trong repo là điều phải cân nhắc chứ không hiển nhiên. - Index là ảnh chụp tĩnh. Trong session, MCP server có file watcher tự sync, nhưng code đổi ngoài session thì phải nhớ
codegraph sync. Quên là agent trả lời trên bản đồ cũ. - CodeGraph chỉ biết cấu trúc tĩnh từ AST. Hỏi về runtime behavior, hot path, dynamic dispatch là ngoài phạm vi của nó.
Khi nào nên bỏ qua: repo nhỏ vài trăm file trở xuống; monorepo đổi quá nhanh (thời gian sync ăn hết phần tiết kiệm); hoặc khi bạn chỉ hỏi một câu rồi thôi. Và lưu ý: CodeGraph bổ sung chứ không thay thế một file CLAUDE.md tử tế. Bản đồ tốt đến mấy cũng không thay được việc dặn agent quy ước của dự án.
Chốt lại
Với mình, tool mới đáng giữ lại trong workflow khi nó thoả ba điều: giải một nỗi đau có thật, số liệu kiểm chứng được, và chi phí gắn vào gần bằng không. CodeGraph thoả cả ba, với điều kiện repo của bạn đủ lớn. Ba lệnh cài, hai phút index, và từ đó mỗi câu hỏi kiến trúc không còn kèm một tràng grep tính tiền nữa.
Bước tiếp theo của mình là bật nó trên dự án thật đang chạy hằng ngày và đo hoá đơn API trước-sau một tuần. Có số sẽ viết tiếp.
Còn nếu bạn đang dùng Claude Code mà hoá đơn hàng tháng làm bạn nhăn mặt, CodeGraph là một van xả. Toàn bộ hệ van còn lại (chọn model rẻ đúng việc, chặn vòng lặp đốt token, harness tự vận hành) mình đóng gói trong bộ skill claude_support, viết từ chính những gì mình chạy hằng ngày.
Nguồn tham khảo: CodeGraph trên GitHub (MIT, Colby McHenry) · Bài hướng dẫn của Tosea.ai (2026-05-22) · Số đo trong bài: lab của tác giả trên MacBook Apple Silicon, CodeGraph 1.1.5, repo OpenClaw 4.304 file, ngày 2026-07-03.
Lưu Hải Long



Bình luận
Chưa có bình luận nào. Hãy là người đầu tiên!
Để lại bình luận